版权声明:自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 4.0
map函数和reduce函数
map函数和reduce函数是交给用户实现的,这两个函数定义了任务本身。
- map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
- reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
使用词频统计来做例子:拆分文件集,copy程序,整合结果。下面是MapReduce函数的核心代码:
1 | map(String key, String value): |
在统计词频的例子里,map 函数接受的键是文件名,值是文件的内容,map 逐个遍历单词,每遇到一个单词w,就产生一个中间键值对
MapReduce工作
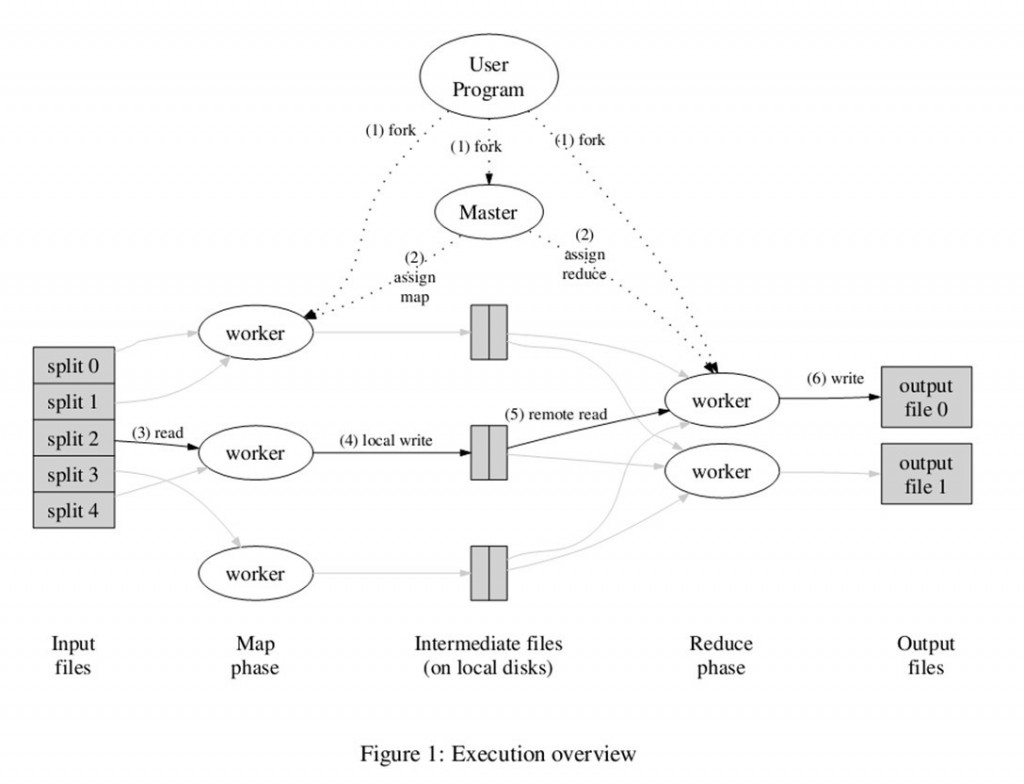
上图是论文里给出的流程图。一切都是从最上方的user program 开始的,user program 链接了MapReduce 库,实现了最基本的Map 函数和Reduce 函数。图中执行的顺序都用数字标记了。
- MapReduce 库先把user program 的输入文件划分为M份(M为用户定义),每一份通常有16MB 到64MB,如图左方所示分成了split0~4;然后使用fork 将用户进程拷贝到集群内其它机器上。
- user program 的副本中有一个称为master,其余称为worker,master 是负责调度的,为空闲worker 分配作业(Map 作业或者Reduce 作业),worker 的数量也是可以由用户指定的。
- 被分配了Map 作业的worker,开始读取对应分片的输入数据,Map 作业数量是由M 决定的,和split一一对应;Map 作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map 函数,map 函数产生的中间键值对被缓存在内存中。
- 缓存的中间键值对会被定期写入本地磁盘,而且被分为R 个区,R 的大小是由用户定义的,将来每个区会对应一个Reduce 作业;这些中间键值对的位置会被通报给master,master 负责将信息转发给Reduce worker。
- master 通知分配了Reduce 作业的worker 它负责的分区在什么位置(不止一个地方,每个Map 作业产生的中间键值对都可能映射到所有R 个不同分区),当Reduce worker 把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce 作业(因为分区少),所以排序是必须的。
- reduce worker 遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce 函数,reduce 函数产生的输出会添加到这个分区的输出文件中。
- 当所有的Map 和Reduce 作业都完成了,master 唤醒正版的user program,MapReduce 函数调用返回user program 的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
用户的权利
用户最主要的任务是实现map 和reduce 接口,但还有一些有用的接口是向用户开放的。
- input reader:这个函数会将输入分为M个部分,并且定义了如何从数据中抽取最初的键值对,比如词频的例子中定义文件名和文件内容是键值对
- partition function:这个函数用于将map函数产生的中间键值对映射到一个分区里去,最简单的实现就是将键求哈希再对R取模
- compare function:这个函数用于Reduce作业排序,这个函数定义了键的大小关系
- output writer:负责将结果写入底层分布式文件系统
- combiner function:实际就是reduce 函数,这是用于前面提到的优化。比如统计词频时,如果每个
- map 和reduce 函数
参见 csdn